Introduction
Software teams are no longer judged only by how quickly they release features. They are also judged by how well those features perform in production. A fast release means very little if the application becomes unstable, alerts become noisy, response time drops, or customers lose trust in the service.
This is the reality of modern engineering.
Today’s systems run on cloud platforms, containers, APIs, automation pipelines, distributed services, and shared infrastructure. These environments help teams move faster, but they also increase complexity. A small failure in one layer can affect many services. A weak monitoring setup can hide important problems. A rushed release can create instability that spreads quickly across the platform.
That is why reliability has become a core engineering skill.
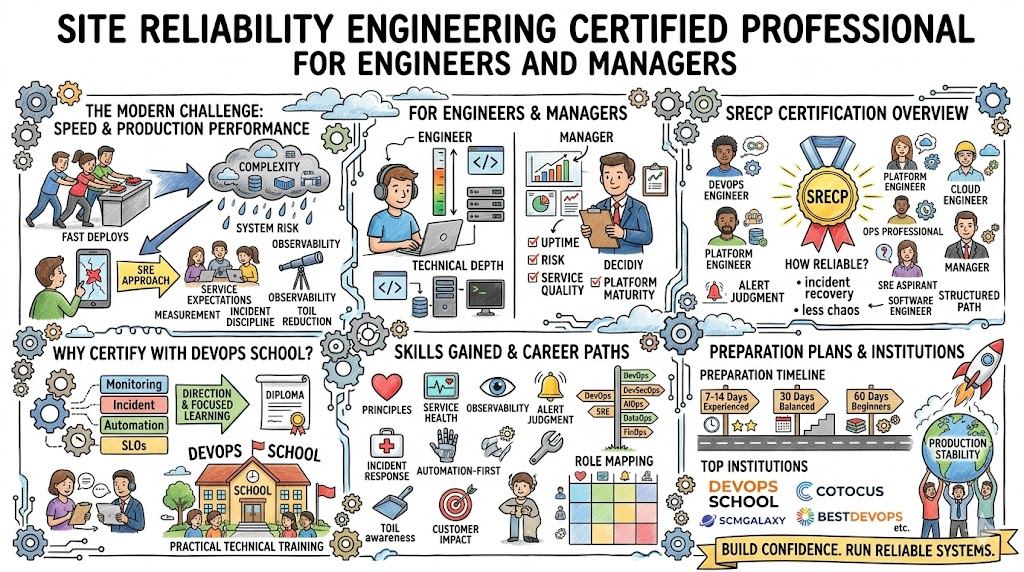
Site Reliability Engineering, widely known as SRE, gives teams a practical way to manage this complexity. It helps them create reliable systems through measurement, automation, observability, incident discipline, and long-term operational improvement. Instead of waiting for issues and reacting under pressure, SRE encourages teams to define service expectations, reduce manual effort, and improve production quality in a structured way.
For engineers, this creates stronger technical depth.
For managers, it creates better decision-making around uptime, service quality, support load, and platform maturity.
The Site Reliability Engineering Certified Professional, or SRECP, is designed for professionals who want to learn these ideas in a clear and career-focused way. It is useful for DevOps engineers, SRE aspirants, cloud professionals, platform engineers, operations teams, and managers who want to understand reliability in a more complete way.
This guide explains SRECP from a fresh and practical angle. It covers what the certification is, why it matters, what you learn, who should take it, how to prepare, which learning path fits your role, and what your next certification move could be.
What is Site Reliability Engineering Certified Professional (SRECP)?
Site Reliability Engineering Certified Professional is a professional certification built for people who want to strengthen their understanding of service reliability, operational excellence, observability, and production engineering.
In simple language, it teaches you how to run software systems with more control, more visibility, and less operational chaos.
That is important because many professionals already do reliability work without using the full SRE model. A DevOps engineer may automate deployments. A cloud engineer may manage uptime. A platform engineer may support internal systems. A system administrator may handle incidents. A manager may be responsible for escalations and service quality. All of these people touch reliability, but often only from their own side.
Why it Matters in Today’s Software, Cloud, and Automation Ecosystem
Modern software delivery is built for speed. Teams deploy more often, scale faster, and work across many integrated systems. While this creates business value, it also increases operational pressure. Reliability becomes harder when systems are distributed, constantly changing, and deeply connected.
This is why SRE matters so much today.
Traditional operations often focused on maintaining infrastructure and responding to problems when they appeared. Modern environments need something more mature. They need a model that helps teams define service quality, measure real performance, reduce unnecessary operational effort, and respond to failure without losing control.
SRE gives teams that model.
It helps answer practical questions that every serious engineering team eventually faces. How reliable should a service actually be? How do we know when users are having a bad experience? Which alerts deserve action and which ones only waste time? How do we balance new releases with system stability? How do we reduce repeated manual work? How do we recover faster from incidents?
These questions are not only technical. They also affect business trust, customer satisfaction, engineering productivity, and operational cost.
For engineers, SRE makes production work more intelligent and more measurable.
For managers, it creates a better way to discuss service health, risk, operational readiness, and platform improvement.
That is why Site Reliability Engineering is no longer a niche topic. It is becoming a normal expectation in modern software, cloud, and platform careers.
Why Certifications are Important for Engineers and Managers
Experience teaches a lot, but experience alone does not always create complete understanding. Many professionals become very strong in one part of operations while staying weak in another. One engineer may know monitoring tools well but not understand service-level thinking. Another may know infrastructure automation but not know how to reduce toil. Someone else may be excellent during incidents but weak at prevention and long-term improvement.
This is where certification becomes useful.
A good certification creates structure. It helps professionals learn the right topics in the right order. It also helps them connect separate ideas into one working model. That matters in SRE because reliability is not one skill. It is a combination of engineering habits, service thinking, support discipline, automation, and operational judgment.
For engineers, certification gives direction. It makes learning more focused. It also helps them see where their current strengths and gaps are. On top of that, it improves career visibility by showing that their knowledge is not random or informal.
For managers, certification provides a framework. Managers need to understand how uptime should be discussed, how incidents should be handled, how service expectations should be set, and how operational maturity should improve over time. A good certification helps build that shared language.
Certification does not replace real work. It works best when combined with real projects, production responsibility, and problem-solving. But it can turn scattered experience into a stronger professional foundation.
Why Choose DevOpsSchool?
DevOpsSchool is often chosen by learners who want technical training that feels close to real engineering work. For SRE, that is especially important because reliability is not a purely academic topic. Professionals need to understand how service quality, monitoring, automation, support patterns, observability, and incident workflows connect in actual environments.
Another advantage is that the learning path fits a broad but relevant audience. SRECP is not only for specialists already working under the SRE title. It also matters to DevOps engineers, platform teams, cloud engineers, operations professionals, and engineering managers. A provider that supports both hands-on contributors and decision-makers adds more practical value.
For professionals looking for a certification that is relevant to current industry roles and modern production environments, DevOpsSchool is a sensible choice.
Certification Deep-Dive: Site Reliability Engineering Certified Professional (SRECP)
What is this certification?
SRECP is a professional certification that focuses on modern reliability engineering practices. It teaches how to approach system stability, service health, incident response, observability, automation, and continuous operational improvement as connected parts of the same discipline.
This certification is not just about keeping systems online.
It is about building a mindset that helps professionals improve production systems in a measured and repeatable way.
Who should take this certification?
This certification is a strong fit for:
- DevOps engineers who want deeper production and reliability skills
- SRE aspirants who want a structured learning path
- Platform engineers responsible for stable internal services
- Cloud engineers managing performance, uptime, and availability
- Operations professionals moving toward automation-first support
- Engineering managers who need a clearer understanding of service quality and operational maturity
- Software engineers who work closely with backend systems and production environments
If your work touches production behavior, support readiness, service quality, or automation, this certification can be valuable.
Certification Overview Table
| Certification Name | Track | Level | Who it’s for | Prerequisites | Skills Covered | Recommended Order |
|---|---|---|---|---|---|---|
| Site Reliability Engineering Certified Professional (SRECP) | SRE | Professional | DevOps engineers, SRE aspirants, platform engineers, cloud engineers, operations professionals, engineering managers | Basic understanding of Linux, cloud, CI/CD, monitoring, and production systems is helpful | Reliability engineering, observability, incident handling, service objectives, automation, operational maturity, production stability | Strong first step in the SRE track |
Site Reliability Engineering Certified Professional (SRECP)
What it is
SRECP is a certification path for professionals who want to understand how reliable services are designed, supported, measured, and improved in modern engineering environments.
It is particularly helpful for those moving from reactive support work into a more disciplined reliability approach.
Who should take it
- DevOps engineers
- SRE aspirants
- Platform engineers
- Cloud engineers
- Operations professionals
- System administrators
- Technical leads
- Engineering managers
- Software engineers working near production systems
Skills you’ll gain
- Understanding of core SRE principles
- Better service-health and service-quality thinking
- Stronger observability awareness
- Better judgment around alert quality
- Clearer understanding of service-level concepts
- Better incident-response thinking
- Stronger automation-first habits
- Better awareness of toil and how to reduce it
- Improved production support maturity
- Better connection between engineering work and customer impact
Real-world projects you should be able to do after it
- Define reliability expectations for a service
- Build dashboards for operational review
- Improve alerting so engineers focus on useful signals
- Create a simple incident-response workflow
- Review repetitive support work and identify automation opportunities
- Support release readiness with reliability thinking
- Improve visibility into service health and performance
- Help teams adopt service-level thinking
- Contribute to production stability initiatives
- Support long-term reliability improvement across services
Preparation plan
7–14 days
This path works best for experienced professionals who already work in cloud, DevOps, platform, or operations roles. Use this period for focused revision. Review reliability basics, observability, incident handling, service goals, and automation use cases. This is a short plan, so it assumes your technical foundation is already strong.
30 days
This is the most balanced path for most working professionals. Spend the first stage understanding the concepts properly. Use the second stage to connect those concepts to real production examples. Use the last stage for revision, practical scenario thinking, and personal notes. This approach helps build understanding, not just memory.
60 days
This plan is better for beginners or professionals changing direction. Start with Linux basics, cloud concepts, CI/CD, containers, monitoring, and production support. Then move into SRE principles, observability, service objectives, incident discipline, automation, and reliability-focused workflows. End with small practical exercises and review.
Common mistakes
- Thinking SRE is only monitoring
- Learning tools without understanding the principles behind them
- Ignoring service-level thinking
- Studying incidents without thinking about prevention
- Treating automation as optional
- Preparing only from theory
- Not connecting reliability to business impact
- Failing to relate the topics to real production environments
Best next certification after this
Your next certification should depend on your role and long-term path.
If you want to stay in the same domain, an observability-focused certification is a strong next step.
If you want stronger infrastructure depth, a Kubernetes-related certification is a good choice.
If your goal is broader ownership or leadership, a DevOps or management-oriented certification can be the right move.
Choose your path
DevOps
This path is ideal for professionals focused on automation, CI/CD, infrastructure, and delivery systems. SRECP adds reliability depth and helps DevOps engineers think beyond shipping code into maintaining service quality in production.
DevSecOps
This path fits professionals working where security and delivery come together. SRECP strengthens this route by adding resilience, incident discipline, and operational maturity to secure engineering environments.
SRE
This is the most direct path for professionals who want to specialize in uptime, observability, incident response, and reliability improvement. SRECP is a natural foundation for this track.
AIOps/MLOps
This path is useful for professionals working with machine learning systems or intelligent operations. These environments still need strong service reliability, observability, and disciplined support. SRECP provides that base.
DataOps
Data systems also depend on reliability. Pipelines, transformations, and analytics platforms need predictability and visibility. SRECP helps DataOps professionals add stronger service thinking to data operations.
FinOps
FinOps focuses on cost efficiency and cloud governance. Reliability supports this because unstable systems often create waste, repeated work, and emergency effort. SRECP can therefore complement a FinOps learning journey in a practical way.
Role → Recommended certifications mapping
| Role | Recommended certifications |
|---|---|
| DevOps Engineer | SRECP, DevOps-focused certifications, Kubernetes-related certifications |
| SRE | SRECP first, then observability and advanced reliability certifications |
| Platform Engineer | SRECP plus Kubernetes, Terraform, and platform engineering learning |
| Cloud Engineer | SRECP plus cloud operations or architecture certifications |
| Security Engineer | DevSecOps certifications first, then SRECP for resilience and operational depth |
| Data Engineer | DataOps learning plus SRECP for platform reliability |
| FinOps Practitioner | FinOps learning plus SRECP for efficiency and stability alignment |
| Engineering Manager | SRECP plus leadership-focused DevOps, SRE, or platform strategy certifications |
Next certifications to take
Same track
An observability-focused certification is one of the best next steps after SRECP. Once you understand reliability concepts, stronger skill in metrics, logs, traces, dashboards, and telemetry can make your production decisions much better.
Cross-track
A Kubernetes-related certification is a strong cross-track option. Since many modern workloads run in containerized environments, Kubernetes knowledge can make your reliability skills much more practical.
Leadership
A DevOps or engineering-management-oriented certification is a good leadership step. It suits professionals who want to move from hands-on work into broader platform ownership, operational governance, or team leadership.
List of top institutions which provide help in Training cum Certifications for Site Reliability Engineering Certified Professional (SRECP)
DevOpsSchool
DevOpsSchool is the direct provider of the SRECP certification, so it is the most aligned option for learners who want official guidance and structured preparation. It is suitable for both working engineers and managers who want practical learning in reliability engineering.
Cotocus
Cotocus can be useful for professionals looking for implementation-focused technical support and learning. It may help learners who want practical exposure to cloud, automation, and engineering workflows connected to reliability.
Scmgalaxy
Scmgalaxy is known for learning around DevOps, automation, and engineering tools. It can be helpful for professionals who want to strengthen technical fundamentals before moving deeper into specialized SRE topics.
BestDevOps
BestDevOps is often recognized in the broader DevOps and cloud training ecosystem. It can support learners who want structured education across automation, infrastructure, and role-based engineering practices.
devsecopsschool.com
This platform is useful for professionals who want to combine reliability thinking with secure delivery practices. It supports engineers working in environments where resilience and security both matter.
sreschool.com
SRESchool is naturally relevant for learners who want a stronger focus on reliability engineering. It can support deeper understanding in service health, observability, incidents, and operational maturity.
aiopsschool.com
AIOpsSchool can be useful for professionals interested in intelligent automation and analytics-driven operations. It is a good complementary option for people exploring advanced operational paths.
dataopsschool.com
DataOpsSchool is helpful for professionals working on data platforms, pipelines, and analytics systems. It supports learners who want stronger operational consistency and service thinking in data-heavy environments.
finopsschool.com
FinOpsSchool is relevant for professionals focused on cloud cost governance, optimization, and efficiency. Since reliable systems often support better financial outcomes, it can complement SRE learning well.
FAQs
1. Is SRECP a beginner-level certification?
It is better described as a professional-level certification. Beginners can still take it, but they usually need more time and stronger basics before they feel comfortable with the material.
2. How difficult is the SRECP certification?
The difficulty is moderate to high depending on your background. Professionals already working in DevOps, cloud, platform, or operations roles generally find it easier.
3. How much time should I prepare?
For many working professionals, 30 days is a practical target. Experienced engineers may need less. Beginners may need around 60 days.
4. Do I need prior operations experience?
It helps, but it is not mandatory. DevOps, cloud engineering, backend development, platform work, and system administration can all support SRE learning.
5. Is SRECP useful for software engineers?
Yes. Software engineers who work near backend systems, APIs, cloud services, or production releases can benefit a lot from understanding reliability better.
6. Is it only for people with the SRE title?
No. It is useful across DevOps, cloud operations, platform engineering, support engineering, and management roles.
7. Will it help with career growth?
Yes. It can strengthen your profile for reliability-focused roles and improve your readiness for production ownership responsibilities.
8. Is this certification useful for managers?
Yes. Managers benefit because it helps them understand service quality, uptime, incident readiness, and team maturity in a more structured way.
9. What should I study before starting?
Linux basics, cloud concepts, monitoring, containers, CI/CD, and production support fundamentals are all useful preparation topics.
10. Is SRECP only about monitoring and alerts?
No. Monitoring is only one part of reliability work. The certification also covers service goals, automation, incident discipline, observability, and operational improvement.
11. Should I take Kubernetes certification before SRECP?
That depends on your role. If your current work is more reliability-focused, SRECP is a strong first step. If your environment is deeply Kubernetes-based, both paths can support each other well.
12. Will SRECP help in real-world projects?
Yes. Its value becomes much stronger when you apply it to dashboards, alerting, incidents, automation, and service-improvement efforts in production.
FAQs on Site Reliability Engineering Certified Professional (SRECP)
1. What does SRECP stand for?
It stands for Site Reliability Engineering Certified Professional.
2. What is the main purpose of this certification?
Its main purpose is to help professionals understand and apply reliability engineering practices in modern production systems.
3. Is SRECP a good option for DevOps engineers?
Yes. It is a strong next step for DevOps professionals who want deeper reliability and operational maturity.
4. Can managers benefit from SRECP?
Yes. It helps managers build better judgment around service health, incidents, uptime, and operational readiness.
5. Is SRECP relevant in cloud-native environments?
Yes. Cloud-native systems are exactly where structured reliability practices become highly valuable.
6. What makes it different from general operations learning?
It focuses on engineering-led reliability rather than only reactive support or manual troubleshooting.
7. Is SRECP useful for platform engineers?
Yes. Platform engineers can use it to improve stability, observability, and production discipline across shared services.
8. What is the biggest value of SRECP?
Its biggest value is that it turns scattered operational experience into a clearer and more complete reliability mindset.
Conclusion
The Site Reliability Engineering Certified Professional certification is a strong choice for professionals who want to build serious capability in modern reliability work. It does not stay limited to one tool, one cloud platform, or one narrow support activity. Instead, it helps learners understand how service quality, observability, automation, incident response, and system stability connect inside real engineering environments. That makes it highly relevant for DevOps engineers, SRE aspirants, cloud professionals, platform teams, software engineers, and engineering managers. In today’s software world, users expect services to be fast, dependable, and always available. SRECP offers a structured and practical path to build the mindset and skills needed to support that expectation with confidence.